昳幙妋擣偺帪娫傕抁弅丄儖儞僶傕巊偭偨僋儔僂僪僔儈儏儗乕僞乕偺壜擻惈偲偼
{kind=link}
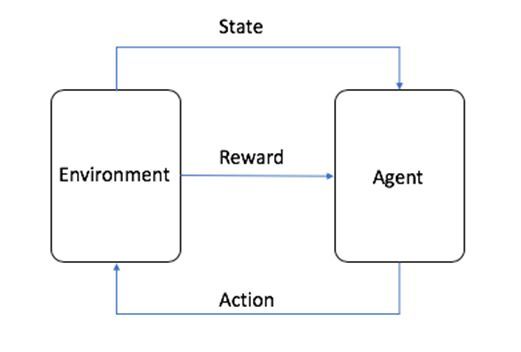
嫮壔妛廗丗僄乕僕僃儞僩乮Agent乯 偑傾僋僔儑儞乮Action乯 傪婲偙偟丄偙傟偵傛偭偰堷偒婲偙偝傟偨僄乕僕僃儞僩廃傝偺娐嫬曄壔傪僗僥乕僩乮State乯偲偟偰丄傾僋僔儑儞偺椙偟偁偟傪曬廣乮Reward乯 偲偟偰僄乕僕僃儞僩偵曉偡丅曬廣傪寛傔傞張棟傪曬廣娭悢偲屇傃丄偙傟偼偁傜偐偠傔掕媊偟偰偍偄偨儖乕儖偵廬偭偰傾僋僔儑儞偺椙偟偁偟偺揰悢晅偗傪偟傑偡乮C乯 2020, Amazon Web Services, Inc. or its affiliates. All rights reserved.