Arm MLプロセッサ、明らかになったその中身
{kind=link}
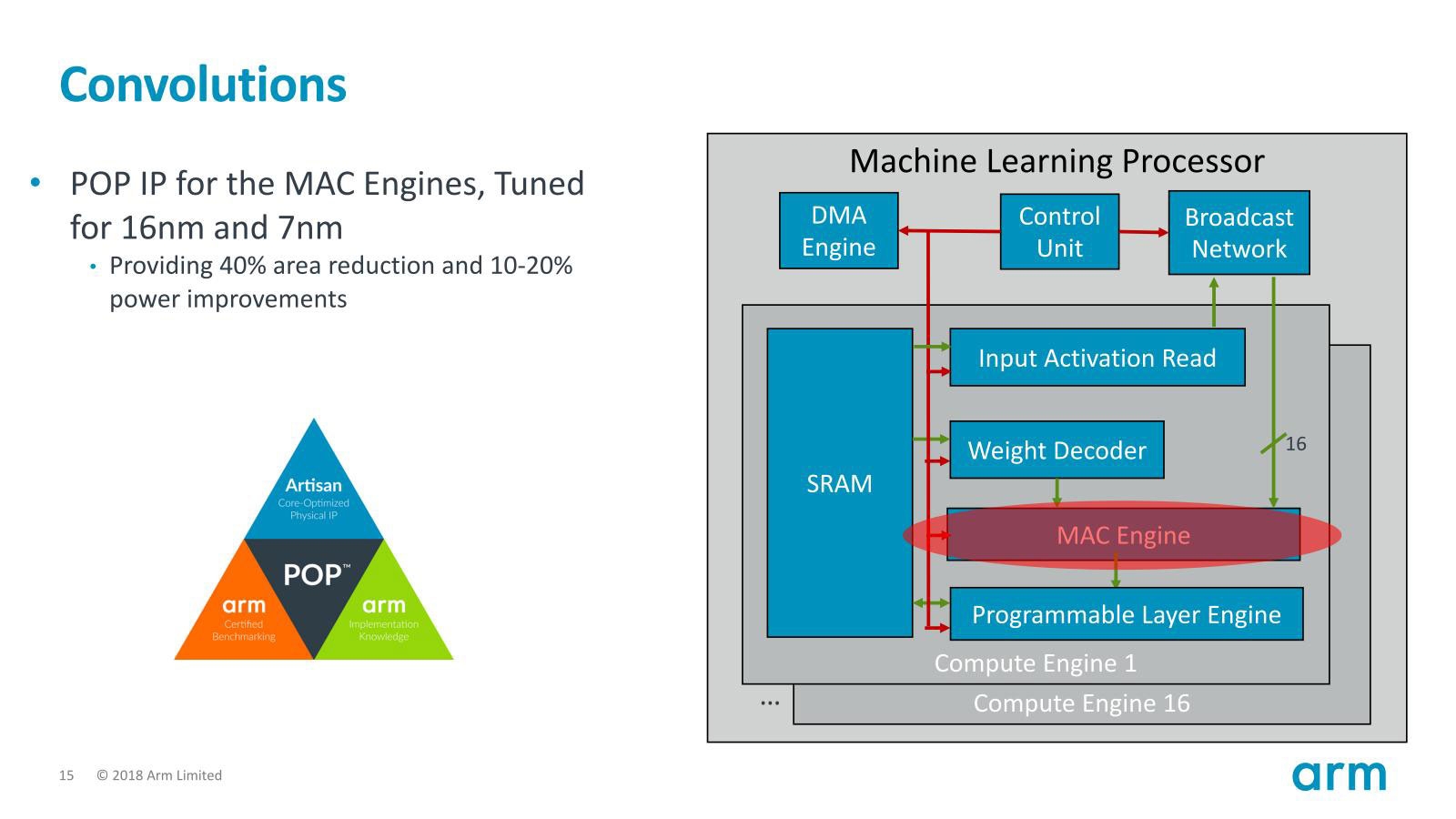
図11(左):先ほどもちょっと触れたが、ここまでは32bitで処理されてきたデータがここで8bitに戻される。桁落ちとか誤差の拡大を防ぎつつデータを小さく抑えられるという意味で、賢明なロジックである/図12:16nmと書いてはあるが、実際にはTSMCの12FFCあたりがターゲットなのではないかと思う。Area reductionが40%というのも、128演算のSIMD Addなんぞがあることを考えれば妥当なところかと思う 出典:Arm(クリックで拡大)